
Thuật toán phát hiện các liên kết bất hợp pháp sử dụng quy tắc kết hợp
Giới thiệu
Các liên kết bất hợp pháp (hay liên kết độc hại) đã và đang xuất hiện thường xuyên thông qua các mạng xã hội với tốc độ "chóng mặt", mang đến nguy cơ gây mất an toàn cho người dùng. Các liên kết này chuyển hướng người dùng đến các trang web lừa đảo. Các trang web này đánh cắp thông tin người dùng bằng cách sử dụng hình thức thông tin giả mạo nội dung hoạt động và chèn các câu lệnh nguy hiểm bên trong các liên kết [2, 3]. Dẫn đến, các cuộc tấn công cài đặt mã độc trên máy khách nhằm kiểm soát máy tính và phát tán mã độc sang các máy khác trên cùng một mạng [4, 5].
Các trang web độc hại thường được ngụy trang giống như trang web đáng tin cậy của các ngân hàng, cơ quan chính phủ hay các trang web thương mại điện tử. Mã độc hại được tự động tải xuống từ máy chủ của tin tặc mà không cần sự cho phép của người dùng để khởi tạo một cuộc tấn công [6]. Hành vi này là dấu hiệu quan trọng để phát hiện một cuộc tấn công web.
Trong những năm gần đây, nhiều phương pháp phát hiện tấn công đã được phát triển, bao gồm: phát hiện các trang web đáng ngờ dựa trên nội dung [7], đào tạo người dùng [8]; các phương pháp phát hiện sử dụng danh sách trắng và danh sách đen…. Hầu hết, các trình duyệt web đều tích hợp phát hiện các liên kết bất hợp pháp dựa trên danh sách trắng và danh sách đen. Tuy nhiên, hiện vẫn chưa có phương pháp tiếp cận có độ chính xác 100%. Hơn nữa, những kẻ tấn công có thể sử dụng các lỗ hổng XSS hay SQL của máy chủ để chèn (insert) các câu lệnh độc hại được che đậy như các câu lệnh hợp pháp lên các máy chủ.
Cơ sở toán học của công nghệ tf-idf và máy vector hỗ trợ
Công nghệ Tf-idf
Công nghệ tf-idf là một phương pháp thống kê được sử dụng để đánh giá tầm quan trọng của một từ trong ngữ cảnh của tài liệu cụ thể trong bộ sưu tập tài liệu hoặc văn bản. Trọng số của một từ nhất định tỷ lệ thuận với số lượng từ được sử dụng trong tài liệu và tỷ lệ nghịch với tần suất của các từ trong các tài liệu khác trong bộ sưu tập.
Công nghệ tf-idf được áp dụng trong bài toán phân loại nhằm mục đích biến đổi tập hợp từ trong các yêu cầu thành vector sử dụng trong việc phân loại. Đối với mỗi yêu cầu, tác giả sẽ coi các từ như một phần của yêu cầu. Đối với mỗi từ t trong yêu cầu d, trong bộ các yêu cầu D, các công thức được sử dụng:

Trong công thức (1) các giá trị tf, idf được tính như sau, với v là các từ còn lại trong liên kết d:

Sau khi ứng dụng công nghệ tf-idf vào bộ dữ liệu có sẵn, chúng ta sẽ nhận được bộ vector kết quả. Đây là một bước quan trọng trong quá trình phân loại sử dụng thuật toán học máy vì hầu hết các thuật toán này đều làm việc với các giá trị số.
Máy Vector hỗ trợ
Máy vectơ hỗ trợ (Support Vector Machine - SVM) đề cập đến các phương pháp phân loại tuyến tính. Hai tập hợp các điểm thuộc hai lớp khác nhau được phân tách bằng một siêu phẳng trong không gian này. Đồng thời, siêu phẳng được xây dựng theo cách sao cho khoảng cách từ nó đến các thể hiện gần nhất của cả hai lớp (vectơ hỗ trợ) là tối đa, đảm bảo độ chính xác cao nhất của phân loại.
Bài toán phân loại tổng quát là < X, Y, y*, Xl > với X là không gian đối tượng, Y là tập đích, y*: X → Y là ánh xạ vào tập đích với các giá trị đã được định nghĩa trước cho từng đối tượng.
Trong bài toán phân lớp X = Rn, Y={-1, +1} mục đích là tìm một phân lớp tuyến tính cho bộ dữ liệu:

Với  biểu diễn của một đối tượng - vector
biểu diễn của một đối tượng - vector 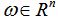 và
và 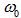 là ngưỡng hay gọi là tham số của thuật toán.
là ngưỡng hay gọi là tham số của thuật toán.
Biểu thức  siêu phẳng. Vấn đề được đặt ra là cần cực đại hóa khoảng cách từ siêu phẳng này đến các điểm gần nhất của mỗi lớp.
siêu phẳng. Vấn đề được đặt ra là cần cực đại hóa khoảng cách từ siêu phẳng này đến các điểm gần nhất của mỗi lớp.
Với tất cả các đối tượng  , ta có:
, ta có:

Điều kiện -1 ≤< ω, x > - ω0 ≤ +1 tạo một đường phân chia giữa các lớp của dữ liệu. Không có bất kỳ một điểm nào của dữ liệu nằm trên đường phân chia này. Hai biên của vành phân chia này là hai siêu phẳng song song cùng hướng với vector ω. Những điểm nằm gần vành phân chia nhất sẽ nằm trên các đường biên này.
Bài toán xác định siêu phẳng tối ưu nhất chính là bài toán cực tiểu hóa bình phương khoảng cách với l điều kiện (5) và (n + 1) biến số:

Khi ứng dụng định lý Kun-Taker thì bài toán trở nên tương đương với bài toán xác định giá trị tối ưu hàm số Lagrange.

Với λ = (λ1, λ2,…, λn) là vector hai biến, thực hiện tính toán:

Thay thế (8) và (9) vào trong công thức Lagrange, nhận được kết quả:

Vector ω được tính toán theo công thức (8). Để tìm giá trị của ω0 cần chọn một vector  và tính ω0 từ biểu thức
và tính ω0 từ biểu thức  . Từ kết quả tính toán của thuật toán phân lớp, có thể xác định hàm dấu cho các đối tượng:
. Từ kết quả tính toán của thuật toán phân lớp, có thể xác định hàm dấu cho các đối tượng:

Với (11) WAF có thể xác định lớp của các đường dẫn tới từ trình duyệt.
Khi kiểm nghiệm thuật toán SVM với một số bộ dữ liệu cho trước, nhận thấy thuật toán được coi là thuật toán nhanh nhất tìm hàm phân chia, có nghiệm duy nhất và tìm siêu phẳng phân chia đối tượng với biên là lớn nhất. Chính vì vậy có thể nói đó là sự phân loại đáng tin cậy [9, 10].
Tuy nhiên, thuật toán SVM vẫn tồn tại nhược điểm là yêu cầu tài nguyên tính toán cao khi số lượng dữ liệu tăng lên, kết quả không chuẩn xác nếu như có nhiều dữ liệu nhiễu và không có phương pháp tự động xác định nhân của máy vector hỗ trợ trong trường hơp phân chia dữ liệu phi tuyến.
Như vậy, cơ sở toán học của công nghệ tf-idf và máy vector hỗ trợ đã được trình bày trong mục 2. Mục 3 sẽ trình bày ưu, nhược điểm của những phương pháp nghiên cứu trước đó trong việc phát hiện đường dẫn độc hại và mô tả kiến trúc của hệ thống thử nghiệm của tác giả.
Kiến trúc hệ thống thử nghiệm
Có hai cách tiếp cận chính để phát hiện các cuộc tấn công từ dữ liệu mạng: phát hiện dựa trên chữ ký và phát hiện bất thường [11 - 13]. Phương pháp phát hiện dựa trên chữ ký cho phép chuyên gia phân tích các cuộc tấn công bằng cách tìm kiếm các chữ ký tấn công được xác định trước. Vì cách tiếp cận này có độ chính xác cao nên nó được sử dụng thành công trong việc phát hiện các cuộc xâm nhập. Tuy nhiên, nhược điểm của phương pháp này không thể phát hiện các cuộc tấn công nếu như không được lập trình trước. Do đó, nó dễ bị bỏ qua tất cả các loại tấn công mới nếu hệ thống không được cập nhật với các chữ ký của tấn công mới nhất.
Phương pháp phát hiện bất thường dựa trên kiểm tra hành vi bình thường của người dùng và phát hiện một cuộc tấn công, quan sát các mẫu đi chệch khỏi các quy tắc đã thiết lập. Các hệ thống sử dụng phương pháp phát hiện bất thường có thể phát hiện các cuộc tấn công mới. Tuy nhiên, số lượng cảnh báo sai có khả năng tăng lên, bởi vì không phải tất cả các dị thường đều là sự xâm nhập. Từ những ưu điểm và nhược điểm của các phương pháp trên, tác giả khuyến nghị sử dụng một hình thức kết hợp cả hai phương pháp này. Đầu tiên, WAF sử dụng một phương thức chữ ký để xác định các tải trọng (payload) bất hợp pháp đã biết. Và sau đó, phương pháp học máy được sử dụng để xác định các liên kết bất hợp pháp cho tất cả các liên kết đáng ngờ.

Hình 1. Vị trí của tường lửa ứng dụng trong hệ thống bảo đảm an toàn thông tin
Cách tiếp cận của tác giả dựa trên việc phát hiện các liên kết bất hợp pháp như một phần của các yêu cầu HTTP được đăng ký bởi hầu hết các máy chủ web phổ biến (ví dụ: Apache). Tất cả các yêu cầu được gửi từ trình duyệt web đến máy chủ web sẽ được kiểm tra bởi tường lửa ứng dụng web. WAF [14] phân tích tất cả các yêu cầu và quyết định có thực hiện trên máy chủ hay không.
Phương pháp phát hiện dựa trên chữ ký:
Khi nhận được các yêu cầu từ người dùng, thực hiện so sánh các tải trọng được lưu trữ trong cơ sở dữ liệu từ trước như một phần của các yêu cầu được gửi từ trình duyệt của người dùng.
Phương pháp phát hiện bất thường
Sử dụng phương pháp vectơ hỗ trợ để xác định ngưỡng để kiểm tra một tập dữ liệu đã cho trước, sau khi kiểm tra với sự trợ giúp của SVM [15-17], tiến hành chặn các liên kết nếu liên kết thuộc về loại liên kết bất hợp pháp. Nếu không, liên kết sẽ được thực hiện trên máy chủ tương ứng.

Hình 2. Sơ đồ hoạt động của hệ thống
Thuật toán phát hiện đường dẫn bất thường dựa trên luật kết hợp
Trong [18], phương pháp sử dụng Máy Vector hỗ trợ để kiểm tra các liên kết bất hợp pháp của tác giả đã mang lại kết quả chính xác với khoảng 98% xác suất phân loại đúng. Do đó, tác giả đề xuất một quy tắc kết hợp sử dụng công nghệ SVM và tf-idf để cải thiện tính chính xác của việc phát hiện các liên kết bất hợp pháp.
Thuật toán đề xuất bao gồm 2 giai đoạn: giai đoạn huấn luyện và giai đoạn phát hiện. Tại thời điểm này, tác giả xem xét hiệu suất của từng giai đoạn của thuật toán.
Giai đoạn huấn luyện bao gồm 3 bước chính:
Bước 1: Mô-đun khai thác được sử dụng để lọc các phần cần thiết cho môđun không gian vectơ từ tập hợp các request nhận được từ trình duyệt của người dùng, bao gồm các liên kết, tải trọng, ký tự đặc biệt. Tại bước này, thực hiện tính toán sự xuất hiện của các ký tự quan trọng mới và lưu chúng trong cơ sở dữ liệu.
Bước 2: Môđun không gian vectơ được sử dụng để chuyển đổi dữ liệu chuỗi thành các vectơ. Sử dụng công nghệ tf-idf tác giả có thể đánh giá tầm quan trọng của các ký hiệu từ và từ khóa trong chuỗi.
Bước 3: Môđun xử lý dữ liệu sử dụng SVM để phân loại các liên kết đến một tập dữ liệu nhất định và đánh giá độ chính xác của các liên kết bất hợp pháp F1score.
Bảng 1. Ký hiệu quan trọng sử dụng trong mục 4

Trước giai đoạn đào tạo, trong quá trình thu thập dữ liệu, thuật toán sẽ định nghĩa các lớp cho dữ liệu là -1 (không tấn công) hoặc 1 (tấn công). Khi phân tích tập dữ liệu này trước khi chạy tường lửa ứng dụng web, tất cả các tải trọng của các yêu cầu bất hợp pháp sẽ được lưu trữ.
Thuật toán huấn luyện
|
Thuật toán 1: Thuật toán huấn luyện |
|
Đầu vào: y, Q Đầu ra: F1score 1: Thu thập dữ liệu: đường dẫn và tải trọng của yêu cầu gửi từ người dùng. 2: Lưu các tải trọng và các ký tự đặc biệt như một phần của yêu cầu. 3: Tính toán tần suất xuất hiện của các ký tự đặc biệt trong tập hợp ký tự đặc biệt. 4: Chuyển đổi dữ liệu dạng chuỗi sang các vector cho tất cả các liên kết bằng cách sử dụng tf-idf. 5: Phân chia tập dữ liệu: dữ liệu huấn luyện 80% (Xtrain, ytrain) và dữ liệu kiểm định 20% (Xtest, ytest). 6: Huấn luyện dữ liệu với thuật toán SVM. 7: Tính toán giá trị F1score sau khi áp dụng SVM. |
Trong giai đoạn huấn luyện của dữ liệu mới, sau quá trình rút dữ liệu, tất cả các tải trọng của các yêu cầu bất hợp pháp sẽ được cập nhật trong cơ sở dữ liệu cho giai đoạn phát hiện trong mô-đun so sánh.
Giai đoạn phát hiện bao gồm 4 mô-đun (mô-đun so sánh và 3 mô-đun như trong giai đoạn huấn luyện). Sau khi thực thi mô-đun trích xuất, tất cả request sẽ được gửi đến mô-đun so sánh. Mô-đun này sẽ so sánh tải trọng của từng request đến với tải trọng của các request bất hợp pháp được lưu trữ trong cơ sở dữ liệu. Nếu tải trọng được tìm thấy, liên kết này sẽ bị chặn. Mặt khác, tất cả dữ liệu của các liên kết khác sẽ được gửi đến mô đun không gian vectơ.
Thuật toán phát hiện sự bất thường
|
Thuật toán 2: Quá trình xử lý dữ liệu trong pha phát hiện |
|
Đầu vào: yêu cầu x Đầu ra: 1 và –1 1: Phân tích yêu cầu x: lưu lại liên kết và tải trọng trong yêu cầu x. 2: So sánh tải trọng bên trong yêu cầu x: nếu tải trọng này được tìm thấy trong cơ sở dữ liệu thì yêu cầu sẽ bị chặn. Trong trường hợp khác thì thuật toán sẽ tiếp tục bước 3. 3: Tính toán tần suất xuất hiện của các ký tự đặc biệt trong x. 4: Chuyển dữ liệu thành dạng vectors 5: Phân loại yêu cầu bằng phương pháp SVM. |
 bằng các sử dụng công nghệ tf-idf.
bằng các sử dụng công nghệ tf-idf.Đánh giá độ chính xác của thuật toán phân loại tấn công trên tài nguyên web
Trong quá trình so sánh, tác giả đánh giá hiệu suất của thuật toán dựa trên độ chính xác, độ bao phủ và độ đo F_meansure. Độ chính xác có nghĩa là tỷ lệ phần trăm kết quả đúng so với tổng giá trị đúng (có sai lầm loại 2).
Ký hiệu TP là True Positive; TN là True Negative; FP là False Positive và FN là False Negative. Thực hiện phép đo Precision – Recall, trong đó, Precision là tỉ lệ số điểm TP trong những điểm được phân loại Positive, còn Recall là tỉ lệ số điểm TP trong số điểm thực sự là Positive. Công thức như sau:

Rõ ràng, Precision và Recall phủ càng cao thì càng tốt. Nhưng trong thực tế, hai giá này không thể đạt được cực đại cùng một lúc và người ta phải tìm kiếm sự cân bằng. Thước đo F1score là trung bình hài hòa giữa Precision và Recall. Nó có xu hướng bằng không nếu hai giá trị này có xu hướng bằng không.

Trong bài báo này, tác giả đã sử dụng bộ dữ liệu bao gồm 4.000 liên kết bất hợp pháp của một số loại tấn công (XSS, SQL injection) và 10.000 liên kết hợp pháp. Bộ dữ liệu từ một số nguồn dữ liệu của các công cụ bảo vệ hệ thống như tệp nhật ký của hệ thống phát hiện và ngăn chặn xâm nhập, yêu cầu HTTP (phương thức GET, phương thức POST) của tường lửa ứng dụng Web. Tác giả đã phân chia các bộ dữ liệu ban đầu thành hai phần riêng biệt với 80% các liên kết để đào tạo và 20% các liên kết để thử nghiệm. Tác giả đã thử nghiệm thêm một số phương pháp học máy để so sánh phương pháp đã đề xuất.

Hình 3. So sánh giá trị F_measure của các phương pháp học máy
Với kết quả thu được là 98.9261%, thuật toán hoạt động tốt hơn so với kết quả được thể hiện trong nghiên cứu [18] là 98%. Kết hợp công nghệ tf-idf (3-gram và đánh giá “tầm quan trọng” của các ký tự đặc biệt) với phương pháp vectơ hỗ trợ cho kết quả tốt nhất của các phương pháp được xem xét trong bài toán phân loại 2 lớp. Hạn chế lớn của phương pháp máy vectơ hỗ trợ nói riêng và các phương pháp học máy như RNN, CNN là đòi hỏi sức mạnh tính toán cao và kích thước bộ từ điển lớn, vì vậy phải mất rất nhiều thời gian để đào tạo khi tăng kích thước của tập dữ liệu ban đầu.
Kết luận
Phát hiện các liên kết bất hợp pháp là một vấn đề khó trong phòng chống tấn công ứng dụng web. Thuật toán phân loại được đề xuất để phát hiện các liên kết bất hợp pháp dựa trên ứng dụng phương pháp học máy với công nghệ tf-idf. Thuật toán phát hiện liên kết bất hợp pháp phân tích các liên kết theo một chuỗi các bước để xác định xem liên kết đó là hợp pháp hay độc hại. Mặc dù thuật toán đề xuất cải thiện độ chính xác phân loại của các liên kết bất hợp pháp, nhưng với sự gia tăng số lượng tham số có trong các yêu cầu, độ chính xác phân loại sẽ giảm. Do đó, trong thời gian tới, cần tìm sự kết hợp của các phương pháp phát hiện bất thường dựa trên học sâu nhằm cải thiện độ chính xác phân loại không chỉ của các liên kết đáng ngờ mới đặc trưng các loại tấn công chưa được định danh.
|
Tài liệu tham khảo [1]. Han Byeong Woo, Yoon Ji Won. Illegal and Harmful Information Detection Technique Using Combination of Search Words // Journal of the Korea Institute of Information Security and Cryptology. – 2016. – Vol. 26, no. 2. – P. 397–404. [2]. Sampat Hemali, Saharkar Manisha, Pandey Ajay, Lopes Hezal. Detection of Phishing Website Using Machine Learning. – 2018. [3]. Gupta Abhishek, Jain Ankit, Yadav Samartha, Taneja Harsh. Literature Survey on Detection of Web Attacks Using Machine Learning. – 2018. [4]. Kim Tae Ghyoon, Choi Young Han, Choi Seok Jin, Lee Cheol Won. System and method for detecting malicious script. – 5 12/2015. – US Patent 9,032,516. [5]. Li Zhi–Yong, Tao Ran, Cai Zhen–He, Zhang Hao. A web page malicious code detect approach based on script execution // Natural Computation, 2009. ICNC’09. Fifth International Conference on. Vol. 6. – IEEE. 2009. – P. 308–312. [6]. Chitra S, Jayanthan K, Preetha S, Shankar RN Uma. Predicate based algorithm for malicious web page detection using genetic fuzzy systems and support vector machine // International Journal of Computer Applications. – 2012. – Vol. 40, no. 10. – P. 13–19. [7]. Shahriar Hossain, Zulkernine Mohammad. Trustworthiness testing of phishing websites: A behavior model–based approach // Future Generation Computer Systems. – 2012. – Vol. 28, no. 8. – P. 1258–1271. [8]. Irani Danesh, Webb Steve, Giffin Jonathon, Pu Calton. Evolutionary study of phishing // ECrime Researchers Summit, 2008. – IEEE. 2008. – P. 1–10. [9]. Lifshits Yuri. Support Vector Method // URL: http://logic.pdmi.ras.ru/~ yura/internet/07ia.pdf. - 2006. [10]. Vorontsov KV. Lectures on the support vector method // Computing Center of the Russian Academy of Sciences, Moscow: URL: http://www.ccas.ru/voron/download/SVM.pdf (accessed: 03.03.12). - 2007. [11]. Stasyuk AI, Korchenko AA. A method for identifying anomalies generated by cyberattacks in computer networks // Zahist shformatsl. - 2012. - T. 4, No. 57. - S. 127–132. [12]. Golovko VA, Bezobrazov SV. Design intelligent anomaly detection systems. - 2011. [13]. Petrenko Sergey Anatolyevich. Methods for detecting intrusions and anomalies in the functioning of cybersystems // Transactions of the Institute for System Analysis of the Russian Academy of Sciences. - 2009. - T. 41. - S. 194–202. [14]. Appelt Dennis, Nguyen Cu D, Panichella Annibale, Briand Lionel C. A machine learning driven evolutionary approach for testing web application firewalls // IEEE Transactions on Reliability. – 2018. – Vol. 67, no. 3 – P. 733–757. [15]. Ma Justin, Saul Lawrence K, Savage Stefan, Voelker Geoffrey M. Beyond blacklists: learning to detect malicious web sites from suspicious URLs // Proceedings of the 15th ACM SIGKDD international conference on Knowledge discovery and data mining. – ACM. 2009. – P. 1245–1254. [16]. Basnet Ram, Mukkamala Srinivas, Sung Andrew H. Detection of phishing attacks: A machine learning approach // Soft Computing Applications in Industry. – Springer, 2008. – P. 373–383. [17]. Sahoo Doyen, Liu Chenghao, Hoi Steven CH. Malicious URL detection using machine learning: A survey // arXiv preprint arXiv:1701.07179. – 2017. [18]. Yadav BV Ram Naresh, Satyanarayana B, Vasumathi D. A Vector Space Model Approach for Web Attack Classification Using Machine Learning Technique // Proceedings of the Second International Conference on Computer and Communication Technologies. – Springer. 2016. – P. 363–373. |
Nguyễn Mạnh Thắng, Phạm Ngọc An, Học viện Kỹ thuật mật mã


















