Sử dụng phương pháp học máy để phát hiện Botnet
09:16 | 04/12/2015 | GP ATTM
Bài viết này đề cập đến phương pháp phát hiện botnet sử dụng học máy để phân loại dựa trên tình trạng lưu lượng mạng. Phương pháp này không phụ thuộc vào nội dung gói tin và giao thức truyền tin sử dụng mã hóa mà các thông tin về lưu lượng mạng được thu thập từ các thiết bị mạng.
Các nghiên cứu phát hiện botnet trước đây chủ yếu dựa vào phương pháp phân tích nội dung gói tin, tìm kiếm các dấu hiệu độc hại của các gói tin TCP/UDP. Phương pháp này được đánh giá là có độ chính xác khá cao, nhưng vẫn có những hạn chế: Các kỹ thuật kiểm tra nội dung gói tin gây tiêu tốn nhiều tài nguyên và thường xử lý chậm; Các bot thế hệ mới thường sử dụng mật mã và một số kỹ thuật làm rối thông tin, chống lại việc kiểm tra nội dung gói tin; Vi phạm tính bí mật.
Kỹ thuật phát hiện botnet và hành vi độc hại thường dựa trên dấu hiệu và sự bất thường. Các kỹ thuật này thường sử dụng hệ thống phát hiện xâm nhập để phát hiện sự tồn tại của các hành vi trên hệ thống mạng, giống như những tác nhân độc hại trên hệ thống, hay mạng bot đã được biết. Kỹ thuật này hoạt động dựa trên việc xây dựng các tập luật và chữ ký. Luật thường được tạo ra bằng phương pháp thủ công và được bổ sung khi phát hiện có phần mềm/ hành vi độc hại mới. Do số lượng phần mềm/ hành vi độc hại ngày một tăng lên nên phương pháp này cần được thay thế bởi một phương pháp tự động.
Nghiên cứu trong bài báo này lựa chọn phương pháp học máy phổ biến - Máy phân loại cây quyết định để phát hiện botnet. Học máy kiểm tra tình trạng mạng của một botnet ở cấp độ dòng TCP/UDP, chia chúng thành nhiều cửa sổ thời gian và trích xuất các đặc tính để phân loại, đánh giá.
Lựa chọn thuộc tính
Trong bảng 1 liệt kê tập hợp 13 thuộc tính được lựa chọn để xây dựng bộ dò trong nghiên cứu này. Thuộc tính gồm các đặc trưng của một dòng hoặc một tập hợp các dòng trong cửa sổ thời gian T cho trước, được biểu thị bằng một giá trị số hoặc một định danh nào đó. Các thuộc tính này có thể là: địa chỉ IP, các cổng nguồn và đích của một dòng. Trong khi các thuộc tính khác, như chiều dài trung bình của các gói đã được trao đổi trong một khoảng thời gian, thì đòi hỏi cần thêm việc xử lý và tính toán. Những thuộc tính này sẽ được sử dụng như là thành phần của vectơ thuộc tính, để nắm bắt các đặc trưng của dòng trong một khoảng thời gian cho trước. Tập hợp các thuộc tính được lựa chọn dựa trên biểu hiện của các giao thức phổ biến và biểu hiện của các botnet đã được biết đến như Storm, Nugache và Waledac.
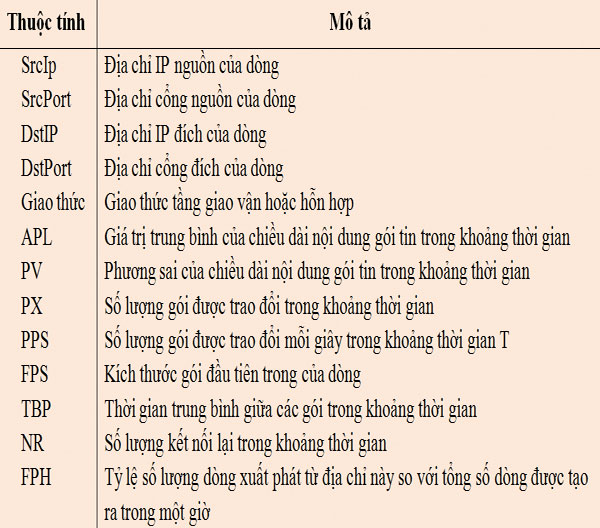
Bảng 1: Các thuộc tính dòng mạng được lựa chọn
Việc lựa chọn các thuộc tính cần phải xem xét đến khả năng chống lại các kỹ thuật che giấu tiềm năng của các bot. Các kỹ thuật nhiễu dòng sẽ có thể được bot sử dụng để lẩn tránh các kỹ thuật phân tích. Một bot có thể chèn các gói tin bất kỳ vào trong thông tin C&C của nó để chống lại phép ánh xạ dựa trên kích thước gói. Để ngăn ngừa sự lẩn tránh của bot, số lượng dòng của một địa chỉ tạo ra được đo và so sánh với tổng số dòng được tạo ra trong một khoảng thời gian nhất định (trong trường hợp này là một giờ). Giá trị này dựa trên căn cứ thực tế là hầu hết các bot sẽ tạo ra nhiều dòng hơn so với các ứng dụng thông thường khi chúng truy vấn các kênh C&C để tìm và thực hiện các nhiệm vụ. Ngoài ra, số lượng các kết nối và kết nối lại mà một dòng tạo ra theo thời gian cũng được tính toán trong trường hợp bot cố gắng kết nối và ngắt kết nối để chống lại phương pháp đo dựa trên kết nối. Cuối cùng, có thể tạo ra danh sách trắng các địa chỉ IP và dịch vụ đã biết để loại bỏ các chương trình bình thường không độc hại có biểu hiện kết nối tương tự như các ứng dụng độc hại cách ly tốt hơn.
Mô hình máy phân loại cây quyết định
Cây quyết định được sử dụng như một mô hình dự báo, với đầu vào là một loạt kết quả quan sát được và đầu ra là một giá trị tính toán từ những giá trị đầu vào cho trước. Các nút lá trên cây quyết định tượng trưng cho một nhóm hoặc một nút được liên kết với hai hay nhiều cây con, được gọi là nút thử nghiệm. Tại nút thử nghiệm, đầu ra được tính toán dựa trên các giá trị thuộc tính của thực thể, mỗi đầu ra đều có khả năng dẫn đến một trong các cây con bắt nguồn từ nút đó. Thuật toán tự động xây dựng nên các cây quyết định thiên về dữ liệu lớn, tạo ra nhiều nhánh cây để nắm bắt được các kịch bản đặc trưng và phức tạp trong tập hợp huấn luyện cho trước. Do đó, các thuật toán “tỉa bớt” được sử dụng cho cây quyết định để thu gọn kích thước của cây và làm giảm độ phức tạp của nó. Mục tiêu của thuật toán tỉa bớt là xác định số lượng sai sót mà cây quyết định sẽ gặp phải trước và sau mỗi giai đoạn tỉa và quyết định xem làm thế nào để việc thực hiện không bị sai sót. Số lượng lỗi có thể được tính theo công thức: E=(e+1)/(N+m). Trong đó, e là số lượng mẫu bị phân loại nhầm ở nút cho trước, N là số lượng mẫu đến nút và m là tập hợp tất cả các mẫu thử nghiệm.
Đánh giá thực tiễn
Một tập hợp các vết lưu lượng mạng được tạo ra gồm cả lưu lượng độc hại và không độc hại, bao gồm cả lưu lượng từ việc áp dụng theo tiêu chuẩn của các ứng dụng mạng phổ biến. Lưu lượng độc hại và không độc hại được trộn lẫn với nhau, sao cho chúng xuất hiện trong cùng các khoảng thời gian và dữ liệu này được dán nhãn để đánh giá độ chính xác của phương pháp.
Hai tập dữ liệu riêng biệt được đưa ra dưới đây bao gồm lưu lượng độc hại của dự án Honeynet (trích trong Chương French) gồm các botnet Storm và Waledac. Lưu lượng không độc hại được biểu diễn bằng hai tập dữ liệu khác nhau (theo tài liệu của phòng thí nghiệm về Lưu lượng tại Ericsson Research, Hungary và Phòng thí nghiệm Quốc gia Lawrence Berkeley National Laboratory - LBNL). Tập dữ liệu của Phòng thí nghiệm Ericsson chứa một số lượng lớn lưu lượng thông thường từ nhiều ứng dụng khác nhau, bao gồm lưu lượng trình duyệt web (HTTP) trò chơi World of Warcraft và các máy khách bittorrent. Dữ liệu LBNL gồm 5 tập dữ liệu được dán nhãn từ D_0,.., D_4 lấy từ mạng của các doanh nghiệp. Thông tin cơ bản của từng tập dữ liệu này được cung cấp trong bảng 2.
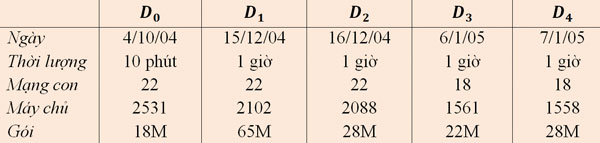
Bảng 2: Thông tin cơ bản của các tập dữ liệu LBNL
Việc ghi lại vết mạng LBNL được thực hiện trong khoảng thời gian 3 tháng (từ tháng 10/2004 đến tháng 1/2005) bao gồm 22 mạng con. Tập dữ liệu bao gồm dữ liệu dấu hiệu cho rất nhiều lưu lượng từ web và thư điện tử đến phương tiện sao lưu và truyền đi. Số lưu lượng rất lớn này là minh họa cho tình trạng sử dụng hằng ngày của các mạng doanh nghiệp.
Để cung cấp tập dữ liệu thực nghiệm, bao gồm cả lưu lượng độc hại và không độc hại, hai tập dữ liệu độc hại này được kết hợp với tập dữ liệu Erikson (không độc hại) thành một tệp tin dấu hiệu đặc trưng. Đầu tiên, các địa chỉ IP của máy bị nhiễm độc được tham chiếu tới 2 trong số các máy có lưu lượng bổ sung. Tiếp theo, tất cả các tệp tin dấu hiệu được vận hành lại sử dụng công cụ TcpReplay trên cùng giao diện mạng để đồng nhất tình trạng mạng, được thể hiện bởi cả 3 tập dữ liệu; dữ liệu vận hành lại này sau đó được thu lại bằng Wireshark để đánh giá. Dữ liệu đánh giá sau cùng (do quy trình này cung cấp) được kết hợp với tất cả 5 tập dữ liệu LBNL, tạo thành mạng con bổ sung để mô phỏng một mạng với kích thước hàng nghìn máy chủ.
Kết quả đánh giá mô hình
Tất cả các thông tin trong chương trình được trích xuất từ một tệp tin cho trước, sau đó được phân tích thành các vectơ thuộc tính thích hợp để phân loại. Có tất cả 1.672.575 dòng mạng trong tập thử nghiệm. Khoảng thời gian duy trì của các dòng rất khác nhau, một số kéo dài không đến 1 giây trong khi một số khác kéo dài đến hơn 1 tuần. Trong các dòng này, chỉ có 97.043 (khoảng 5,8%) là độc hại. Các dòng này tạo ra 111.818 vectơ thuộc tính độc hại và 2.203.807 vectơ thuộc tính không độc hại. Mỗi vectơ đặc trưng tương ứng với một cửa sổ thời gian 300 giây, trong đó ít nhất một gói tin được trao đổi. Các vectơ thuộc tính dòng độc hại là các vectơ được trích xuất ra từ một dòng có liên quan đến dữ liệu botnet Storm và Waledac, còn tất cả các vectơ thuộc tính khác được coi là không độc hại, bao gồm các ứng dụng ngang hàng như Bittorrent, Skype và e-Donkey.
Kỹ thuật đánh giá k-fold cross validation đã được sử dụng với k=10. Tập dữ liệu được chia thành 10 tập hợp con ngẫu nhiên, trong đó 1 tập dùng để đánh giá, 9 tập còn lại dùng để huấn luyện. Quy trình này được lặp đi lặp lại cho đến khi tất cả 10 tập hợp con đều đã được sử dụng làm tập hợp thử nghiệm đúng một lần. Tỷ lệ dương tính đúng và sai của máy phân loại cây quyết định được liệt kê trong bảng 3 dưới đây, là giá trị trung bình của 10 lần chạy.

Bảng 3: Tỷ lệ phát hiện của máy phân loại REPTree (T=300 giây)
Bảng 3 cho thấy máy phân loại cây quyết định có tỷ lệ phát hiện rất cao (trên 90%) và tỷ lệ sai rất thấp. Kết quả này chỉ ra rằng, các botnet được xem xét có những đặc trưng rất khác biệt so với lưu lượng mạng thường ngày.
Kết luận
Phương pháp học máy sử dụng mạng phân loại cây quyết định có những ưu điểm: Sử dụng để phát hiện sự hiện diện của một bot trong suốt vòng đời của nó; Phát hiện dựa trên đặc trưng lưu lượng mạng không phụ thuộc vào việc sử dụng các thuật toán mã hóa; Chi phí tính toán rẻ hơn so với các kỹ thuật khác. Bằng cách chia nhỏ dòng thành các cửa sổ thời gian đặc trưng, việc phát hiện bot có thể nhanh hơn, trước khi Bot kết thúc nhiệm vụ của mình (trong các giai đoạn C&C hay thực hiện tấn công). Với các kết quả trên, có thể kết luận rằng việc lựa chọn phân loại cây quyết định là phù hợp với cơ chế phát hiện botnet dựa trên các thuộc tính dòng.